Big Data has entered the IT vernacular as describing both, the exponential growth of data being generated and consumed by applications, as well as the architectures and processes required to handle these huge amounts of information; volumes that would overwhelm traditional technological solutions.
But more than just defining these new volumes of data as “BIG”, such data exhibits 5 key attributes (5Vs) that need to be considered when processing a dataset. Each of the Vs has implications for handling in and of themselves, but, when combined, present even bigger challenges.
Let’s take look at Big Data’s key attributes ( 5Vs )
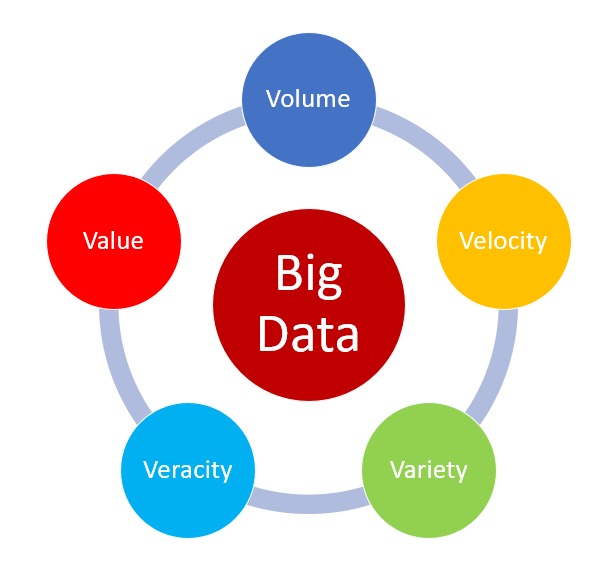 Volume – this is the most obvious of the Vs when considering Big Data. Data is all around us, and with the smartphone explosion, the ability to consume and create data is literally in our hands. There is a claim that the equivalent amount of data created between the beginning of recorded time and 2008 is likely being generated every minute today. That’s some exponential growth right there! These volumes of data, and the need to interrogate them, “break” the traditional database technologies which have served us well up to this point in our data maturity.
Volume – this is the most obvious of the Vs when considering Big Data. Data is all around us, and with the smartphone explosion, the ability to consume and create data is literally in our hands. There is a claim that the equivalent amount of data created between the beginning of recorded time and 2008 is likely being generated every minute today. That’s some exponential growth right there! These volumes of data, and the need to interrogate them, “break” the traditional database technologies which have served us well up to this point in our data maturity.- Velocity – this reflects the speed at which new content is created; every Facebook like, every Instagram post is new data. We don’t even consider it… we just press the requisite button wherever in the world we as individuals might be, and new data is born. This instant data creation, and the need for that data to be immediately consumable by others, means that there’s no time for end of day “batch processing”; data must be seamlessly created and ready for consumption in real-time. Big Data technologies allow for data to be consumed even before it reaches its final storage destination.
- Variety – in the old days (I’ll hesitate to use “good”) data would be created in siloed applications. Each user creating well-structured data via a UI, pushing records to a backend database, to be stored and then reused by other consumers of the application. The data record having the same footprint be it in creation, modification or deletion. Today, we must consider the wealth of types of data that are being created and consumed (photos, videos, multi-user message streams etc). All these various forms of data pulled together to present for example a Facebook wall or a WhatsApp group history to a user – see how we take it for granted? The word used for such data is “unstructured”.
- Veracity – the easiest way to think of this is that, in the past, information was input into forms in application UIs. Logical checks in the code would ensure that, for example, only numbers were put in telephone fields. In this way, data was sanitised before it could enter into the system permanently. Today, information takes more of a ‘free-form’ approach. Have you ever seen twitter refuse to allow you to submit a post because you had input an invalid character, or misspelt a word? Today, the back-end Big Data architectures, with their machine learning and AI capabilities, have become the ‘Rosetta Stone’ to sifting the real data from the jumble.
- Value – probably the most important of them all. It’s quite simple to generate petabytes of data, but to what purpose? Is there anything meaningful in there that could be used to advance knowledge, drive business opportunities, retain customers etc. This is the hardest part, requiring knowledge of what the data might reveal and attempting to marry it to well-defined outcomes. This element harks back to the long history of IT projects, where technology was used to accelerate and grow business – t’was ever thus!
I hope this has proved a useful introduction to the 5Vs of Big Data, and that it might help you hang onto the coat-tails of any 5Vs conversation you find yourself a part of!
UK ServiceNav Product Development Manager; my priority is to be needful of the particular requirements of all ‘English-speaking’ markets where ServiceNav is sold.
I have over 20 years experience of the IT monitoring field - covering a wide variety of products and technologies.